

AI 채팅앱 제타 개발사 스캐터랩, B200 기반 LLM 개발 환경 공개
Elice
2025. 12. 17.
제타가 더 빠르게 성장하기 위해 필요한 것

제타는 사용자가 AI와 함께 내러티브(이야기)를 만들고 상호작용하는 경험을 중심으로 설계된 서비스입니다. 단순히 질문을 입력하고 답변을 받는 대화형 AI를 넘어, 사용자가 능동적으로 스토리를 만들어가는 ‘참여형 AI 경험’을 목표로 하고 있습니다. 이러한 서비스를 구현하기 위해서는 자연스러운 응답 품질, 맥락 안정성, 인터랙션 유지 능력 등이 매우 중요하며, 이는 곧 LLM의 지속적인 고도화와 반복 실험을 필요로 합니다.
스캐터랩은 이미 AWS 기반 환경에서 안정적으로 모델을 학습해왔지만, 국내 환경에서도 동일한 수준의 연구 생산성을 확보할 수 있는지 확인하고자 B200 기반 학습 성능을 면밀하게 검증했습니다. 공정한 비교를 위해 학습 코드, 파라미터, 분산 설정, 데이터 흐름 등을 모두 동일하게 유지하며 실제 환경에 가까운 형태로 연구를 진행했습니다.
H100 대비 최대 3.4배 짧아진 학습 소요 시간
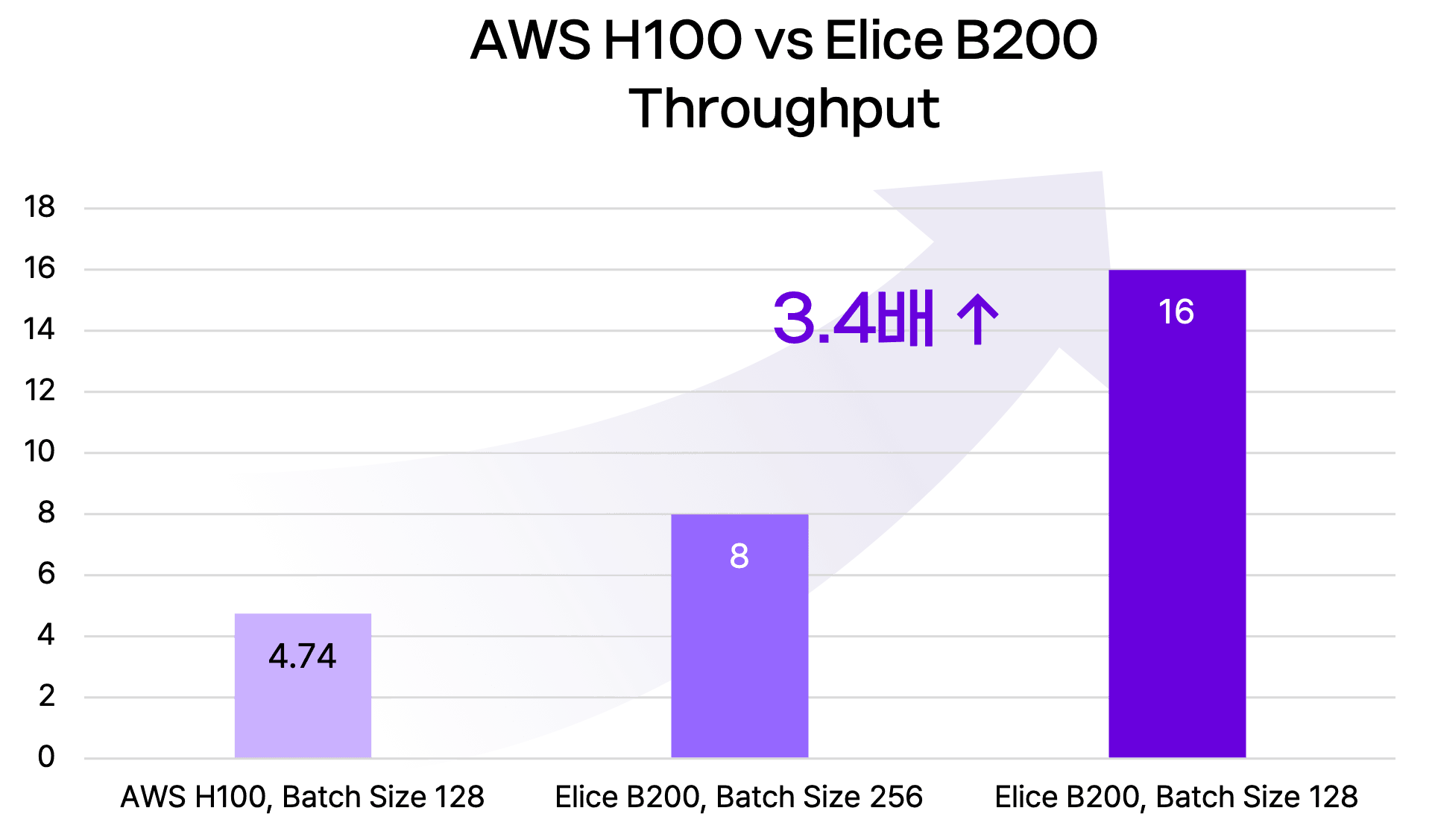
스캐터랩의 AWS 환경은 H100 GPU 8노드(총 64 GPU)로 구성되어 있으며, 엘리스클라우드 역시 동일한 GPU 수를 사용했습니다. AWS에서는 Global Batch Size 128 기준 Step Time(한 번의 학습 단계를 수행하는데 걸리는 시간)이 27초로 측정되었습니다. 동일한 조건에서 B200 환경은 Step Time 8초를 기록해 약 3.4배 더 빠른 속도를 보였습니다. 모델 학습에서 Step Time은 한 번의 업데이트를 수행하는 데 걸리는 시간으로, 이 값이 낮을수록 학습 속도가 크게 향상됩니다. 대규모 모델에서는 Step Time 단축이 곧 실험 가능성 자체를 넓히는 요소이기 때문에, 스캐터랩 입장에서 체감되는 개선 폭은 매우 컸습니다.
초기에는 B200이 Batch Size 256에서도 Step Time 32초 수준을 유지하며 AWS 대비 넉넉한 메모리 구조가 강점으로 확인되었습니다. Batch Size를 두 배까지 늘려도 안정적으로 유지된다는 점은 동일한 시간 안에 더 많은 데이터를 처리할 수 있는 가능성을 보여주었습니다. 분산 학습의 핵심 요소인 InfiniBand 통신 품질 역시 AWS와 동등한 수준으로 확인되었고, 장시간 반복 학습에서도 지연율과 대역폭이 안정적으로 유지되었습니다.
모델 학습의 설계 폭을 넓힌 B200의 메모리 구조
대규모 모델 학습은 다양한 설정과 반복 실험이 연속되는 특성을 갖고 있으며, 설정 하나만 변경해도 전체 클러스터 구성을 다시 잡아야 하는 경우가 많습니다. 때문에 단순 속도보다 더 중요한 것은 개발 과정에서의 안정성과 전략적 유연성입니다. 스캐터랩은 B200 환경에서 이러한 요소가 충분히 확보된다는 점을 확인했습니다.
엘리스클라우드 B200 클러스터는 GPU 메모리 용량이 넉넉해 동일한 노드 수에서도 더 큰 Batch Size를 안정적으로 사용할 수 있었습니다. 이는 더 큰 입력 길이, 더 다양한 병렬화 전략을 시도해볼 수 있다는 의미였습니다. 학습 효율만 높인 것이 아니라 모델 수렴 안정성과 실험 설계의 폭을 넓혀 개발자가 다양한 조합을 실험할 수 있도록 도와주는 기반이 되었습니다.
스캐터랩은 이번 결과가 단순히 B200 GPU의 성능 때문만은 아니라고 평가했습니다. 엘리스클라우드의 AI 전용 IaaS 플랫폼인 ECI(Elice Cloud Infrastructure) 환경 위에서 B200이 안정적으로 운영되었기 때문에 메모리 기반의 유연한 학습 설계와 반복 실험이 가능했다고 분석했습니다. 새로운 실험을 진행할 때마다 환경을 다시 구성해야 하는 부담이 크지 않았고 보다 공격적인 설정을 적용하더라도 학습 안정성이 유지되었다는 점에서 인프라 설계의 중요성을 확인할 수 있었습니다.
더 나은 고객 경험을 위한 기능 고도화
스캐터랩은 연구 과정에서 실제 개발자가 느끼는 사용성 중심의 개선 의견을 정리해 전달했습니다. S3 호환 스토리지는 안정적으로 동작했고, 콘솔 기반 모니터링 기능도 직관적이었지만, 대규모 학습을 준비하는 과정에서 초기 셋업에 시간이 소요된다는 의견이 있었습니다.
엘리스클라우드는 이러한 피드백을 기반으로 SLURM 기반 구성 절차를 매뉴얼 및 템플릿 형태로 정비해 초기 환경 구축 난이도를 낮췄습니다. 또한 노드 초기 이미지를 최신 버전으로 보완해 누구나 더 빠르게 일관된 실험 환경을 구성할 수 있도록 개선했습니다. 대규모 학습 워크로드에 필요한 파일 처리 성능을 확보하기 위해 VAST Data 기반의 고성능 파일 스토리지도 도입 중이며, 이는 향후 더욱 확장된 개발 환경으로 이어질 예정입니다.
엘리스클라우드는 스캐터랩이 전달한 의견을 빠르게 제품 로드맵에 반영해 AI 연구자 및 기업이 더 적은 비용으로 더 많은 실험을 수행할 수 있는 구조를 만들고 있습니다.
대규모 학습 운영에서 확인한 성능 및 안정성
스캐터랩은 엘리스클라우드 B200 클러스터가 초거대 모델 학습에 필요한 성능과 안정성, 그리고 향후 확장 가능성까지 고르게 갖추고 있음을 확인했습니다. 분산 학습 과정에서 GPU 간 통신 지연이나 성능 저하 없이 학습이 안정적으로 유지되었고, 장시간 반복 학습에서도 통신 대역폭과 지연율에 유의미한 변동이 발생하지 않았다는 점을 높게 평가했습니다. 대규모 학습을 안정적으로 수행할 수 있다는 점은 곧 서비스 품질 개선과 운영 효율로 이어질 수 있기 때문입니다.
엘리스클라우드는 앞으로도 자동화, 스토리지, 네트워크 전반에서 기능 확장을 이어가며 더 많은 AI 서비스 운영 조직을 안정적으로 지원할 수 있는 인프라를 제공할 계획입니다.


