
NVIDIA B200은 A100, H100보다 얼마나 빠를까? LLM 학습·추론 분석
Elice
2025. 9. 26.
인공지능 서비스의 성능은 GPU 선택에 따라 크게 달라집니다. 특히 LLM(대규모 언어 모델)과 VLM(비전 언어 모델)의 발전은 GPU를 단순 연산 장치가 아닌 서비스 경쟁력의 핵심 인프라로 만들었습니다. 그러나 사양 비교만으로는 실제 학습·추론 속도를 정확히 예측하기 어렵고, 이로 인해 프로젝트 일정과 비용 구조에 큰 불확실성이 발생합니다.
현재 업계의 주요 선택지는 NVIDIA의 A100, H100, 그리고 최신 아키텍처 기반의 B200입니다. 그러나 최신 제품일수록 실제 성능 데이터가 부족해 선택 과정에서 어려움이 존재합니다.
이에 본 포스팅에서는 엘리스클라우드 VM(Virtual Machine, 가상머신) 환경에서 동일 조건하에 A100, H100, B200의 학습 및 추론 성능의 정량적 차이를 비교 분석하였습니다. 결과를 통해 각 GPU가 AI 서비스와 연구 환경에서 가지는 의미를 명확히 제시하고자 합니다.
벤치마크 환경
본 벤치마크는 실제 AI 서비스를 운영하는 것과 비슷한 상황을 만들기 위해 업계에서 널리 쓰이는 도구와 AI 모델들을 사용했습니다.
학습 단계에서는 LLaMA-Factory를 이용해 두 가지 모델을 학습했습니다. 하나는 텍스트 처리에 특화된 Llama-3.1-8B-Instruct, 다른 하나는 이미지와 텍스트를 함께 다룰 수 있는 Qwen2.5-VL-7B-Instruct입니다. 학습에는 alpaca와 llava-instruct라는 데이터셋을 사용했는데, 이는 모델이 훈련을 받는 교재와 같은 역할을 합니다.
추론 단계에서는 vLLM 환경에서 Llama-3.1-8B-Instruct와 Qwen2.5-32B-Instruct 모델을 실행했습니다. 추론은 학습이 끝난 모델이 실제 문제를 풀고 답을 내놓는 과정으로, 사용자가 체감하는 속도와 품질을 평가할 수 있습니다.
학습 성능 평가는 세 가지 지표로 이루어졌습니다. GPU가 한 번에 처리할 수 있는 데이터 양(최대 배치 사이즈), 배치 한 단위를 처리하는 속도(단일 배치 처리량), 그리고 최종 학습 속도(최대 처리량)입니다.
추론 성능 평가는 다섯 가지 지표를 사용했습니다. 초당 처리 가능한 요청 수(요청 처리량), 초당 처리되는 토큰 수(토큰 처리량), 출력이 생성되는 속도(출력 처리량), 토큰 한 개가 출력되기까지 걸리는 시간(TPOT, Time Per Output Token), 그리고 토큰과 토큰 사이의 지연 시간(ITL, Inter-Token Latency)입니다. 이 지표들은 모두 실제 서비스의 응답 속도와 성능을 결정하는 핵심 요소입니다.
벤치마크 결과: 학습 성능
GPU가 최신 세대로 갈수록 학습 성능은 뚜렷하게 향상되었습니다.
우선 H100은 A100 대비 큰 개선을 보였습니다. GPU 4장을 사용했을 때, Llama 모델의 최대 처리량은 A100에서 4.4에 머물렀지만 H100에서는 22.9로 늘어나 약 5배 차이를 보였습니다. 이는 두 세대 간 아키텍처 변화가 학습 효율에 직접적으로 반영된 결과라고 볼 수 있습니다.
B200은 H100보다 한 단계 더 앞선 성능을 보여주었습니다. 동일하게 GPU 4장을 사용할 경우, 최대 처리량은 H100의 22.9에서 B200의 32.1로 약 1.4배 증가했습니다. 단일 배치 처리 속도 역시 H100보다 약 1.9배 빠르게 측정되었습니다. B200은 연산 구조 자체가 더 효율적으로 설계되어 학습 속도를 크게 끌어올린 것입니다.
확장성 측면에서도 차이가 확인되었습니다. GPU 수를 4장에서 8장으로 늘렸을 때, H100은 처리량이 1.2~1.3배 증가에 그쳤지만, B200은 1.4배 이상 높아졌습니다. 이는 차세대 NVLink 기술로 GPU 간 통신 효율이 개선된 결과로 볼 수 있습니다. 따라서 B200은 대규모 클러스터 환경에서 장기적으로 더 큰 성능 격차를 만들어낼 가능성이 있습니다.
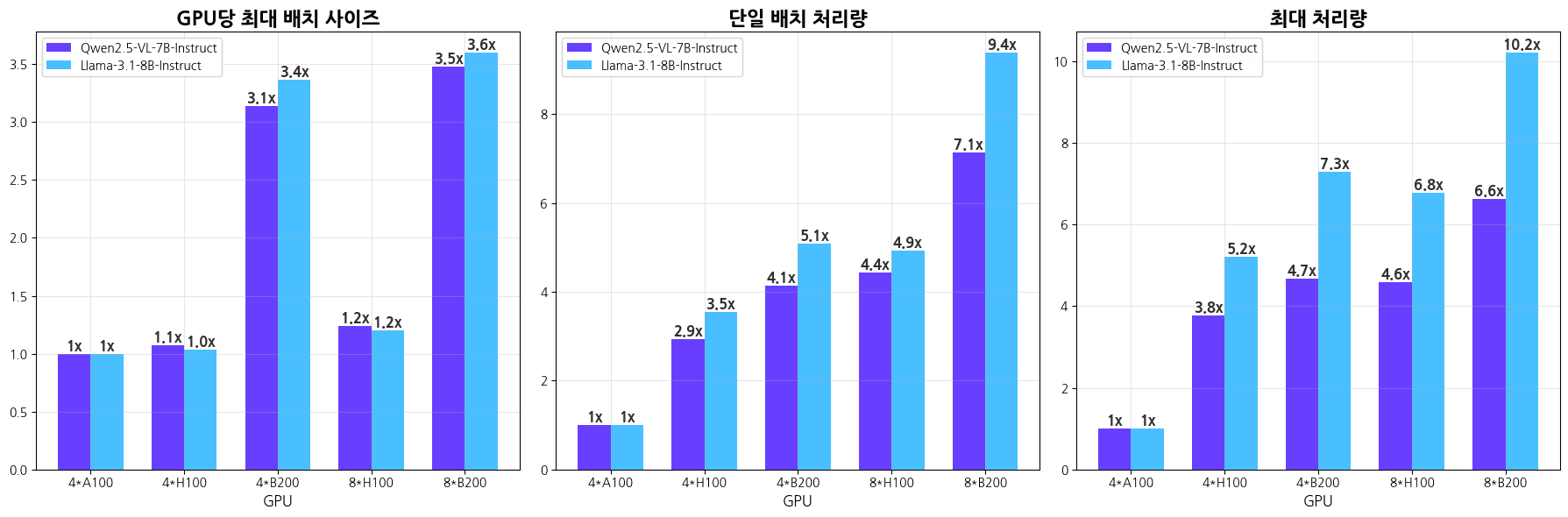
▲ NVIDIA A100 vs H100 vs B200: LLM 학습 단계에서의 GPU 성능 비교 결과
위 그래프는 GPU당 최대 배치 사이즈, 단일 배치 처리량, 최대 처리량을 각각 비교한 결과를 시각적으로 보여줍니다. A100에서 H100, 그리고 B200으로 세대가 전환될수록 모든 지표에서 확연한 성능 향상이 나타나며, 특히 B200은 배치 크기와 처리량 모두에서 뚜렷한 우위를 보였습니다.
벤치마크 결과: 추론 성능
추론 성능은 실제 사용자가 AI 서비스를 이용할 때 가장 직접적으로 체감되는 부분입니다. 아무리 학습이 빨라져도 응답이 느리면 서비스 경쟁력이 떨어지기 때문에, 추론 성능은 GPU 선택에서 핵심 지표라 할 수 있습니다.
이번 실험은 세 가지 상황을 가정해 진행했습니다. 짧은 입력을 긴 출력으로 바꾸는 경우(Short2Long), 긴 입력을 긴 출력으로 바꾸는 경우(Long2Long), 긴 입력을 짧게 요약하는 경우(Long2Short)입니다. 각각 콘텐츠 생성, 문서 변환 등 실제 서비스에서 자주 발생하는 시나리오를 반영했습니다.
H100은 A100보다 명확하게 빠른 결과를 보여주었습니다. GPU 4장 구성에서 Llama 모델의 요청 처리량은 A100의 0.57에서 H100의 2.78 req/s로 약 5배 증가했습니다. 또한 사용자가 체감하는 응답 속도(TPOT)는 121ms에서 38ms로 단축되어, 응답 시간이 3분의 1 수준으로 줄었습니다.
B200은 H100보다도 한 단계 진보한 성능을 기록했습니다. GPU 8장을 사용했을 때 Llama 모델의 요청 처리량은 5.76에서 7.55 req/s로 30%가량 증가했고, TPOT는 18ms까지 줄어 사실상 실시간 대화가 가능한 수준에 도달했습니다. 특히 Qwen 모델에서는 H100 대비 요청 처리량이 2.36에서 6.18 req/s로 약 2.6배 증가해, 특정 모델 구조와 아키텍처 조합에 따라 성능 격차가 더욱 크게 벌어질 수 있다는 점도 확인되었습니다.
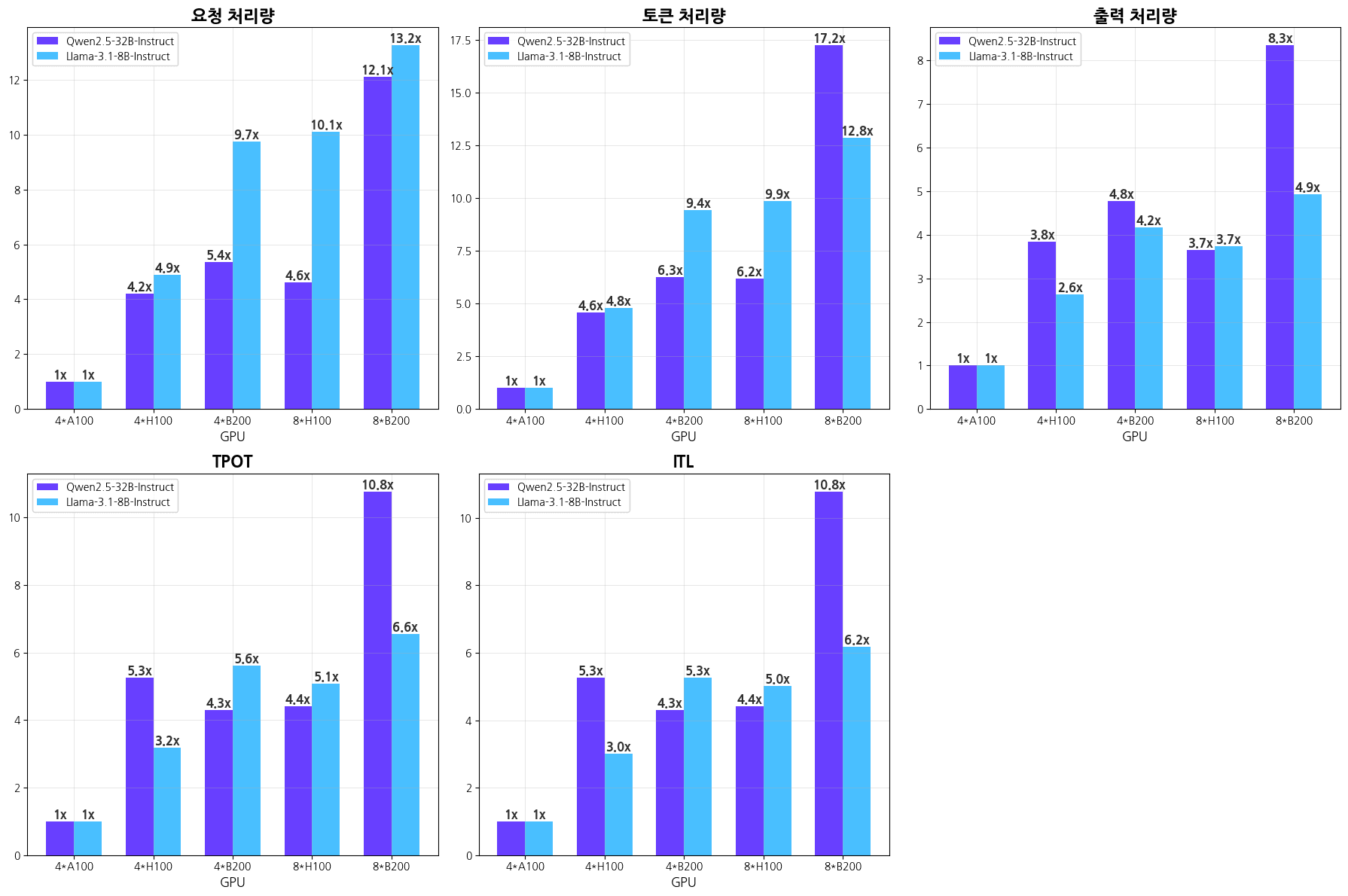
▲ A100 vs H100 vs B200: LLM 추론 성능 비교
벤치마크 결과: 종합
실험 결과는 GPU 세대 교체가 단순한 성능 향상을 넘어 아키텍처적 진보와 모델별 차별적 효과를 동반함을 보여주었습니다.
첫째, 모델별 성능 개선 폭의 차이가 뚜렷하게 나타났습니다. 예를 들어 Qwen 모델의 경우, B200에서 요청 처리량이 H100 대비 약 2.6배 증가하였습니다. 이는 B200의 새로운 연산 아키텍처가 특정 모델 구조와 특히 잘 맞아떨어질 수 있음을 의미합니다. 따라서 GPU 선택은 단순히 최신 제품을 사용하는 것 이상의 의미를 가지며, 개발 중인 모델의 특성과 아키텍처를 고려한 전략적 판단이 필요합니다.
둘째, 확장성 측면에서의 우위가 확인되었습니다. B200은 H100 대비 GPU 확장 시 처리량 증가율이 더 높았습니다.(1.40 vs 1.30배). 이는 차세대 NVLink 아키텍처를 통한 GPU 간 통신 효율 개선에 기인한 것으로 해석됩니다. 결과적으로 B200은 대규모 GPU 클러스터를 활용하는 환경에서 시간이 지날수록 성능 우위를 확대할 가능성이 큽니다.
셋째, 사용자 경험의 질적 변화가 관찰되었습니다. B200은 추론 단계에서 TPOT를 18.5ms까지 단축하여, 사실상 실시간 응답 수준을 구현하였습니다. 이는 단순히 속도가 빠르다는 의미를 넘어, AI 모델과 사용자가 자연스러운 대화 경험을 할 수 있는 새로운 단계로 진입했다는 것을 알 수 있습니다. 앞으로 AI 서비스에서 실시간 응답은 차별화가 아닌 기본적인 수준이 될 가능성이 높다고 볼 수 있습니다.
이러한 결과는 A100, H100, B200이 각각 다른 의미를 지닌 GPU임을 보여줍니다. A100은 비용 대비 안정적인 선택, H100은 현 시점의 표준, B200은 미래의 기준으로 자리잡을 가능성이 점차 분명해보입니다.
결론
이번 벤치마크를 통해 NVIDIA A100, H100, B200의 성능 차이를 학습과 추론 단계에서 정량적으로 확인하였습니다. 세대가 바뀔수록 성능은 뚜렷하게 향상되었으며, 특히 B200은 연산 속도, 확장 효율, 사용자 체감 속도에서 모두 압도적인 우위를 보였습니다.
A100은 여전히 비용 대비 안정성을 원하는 환경에서 유효한 선택입니다. H100은 다양한 워크로드에서 검증된 성능과 안정성을 제공하며, 현 시점에서 가장 실용적인 표준이라 할 수 있습니다. 그러나 B200은 단순한 성능 개선을 넘어 AI 서비스의 질적 변화를 이끄는 GPU라 할 수 있습니다. 실시간에 가까운 추론 속도, 대규모 환경에서도 유지되는 확장성, 특정 모델에서 폭발적으로 나타나는 성능 개선은 B200이 단순히 H100의 후속작이 아니라 새로운 기준점임을 보여줍니다.
따라서 지금 안정적인 도입을 원한다면 H100이 현실적일 수 있습니다. 하지만 차세대 AI 시장의 룰을 만들고, 대규모 연구와 혁신을 주도하고자 한다면 B200은 선택이 아닌 필수가 될 것입니다.
지금 B200을 경험해볼 수 있습니다
엘리스클라우드는 국내 최초 수랭식 NVIDIA B200 클러스터 출시를 기념하여 10월 한 달간 충전 금액의 25%를 추가 크레딧으로 드리는 특별 프로모션을 진행하고 있습니다. AI 인프라의 미래가 될 B200을 가장 먼저, 합리적인 조건으로 만나보세요.
B200, 더 큰 모델에서는 얼마나 강력할까?
이번 실험은 시작에 불과합니다. Llama-3.1-8B, Qwen2.5 같은 중형 모델을 넘어 더 큰 모델을 대상으로 한 벤치마크가 곧 공개될 예정입니다. B200이 대규모 워크로드에서도 얼마나 차별적인 성능을 발휘하는지, 다음 결과에서 확인하실 수 있습니다.
Appendix
시나리오별 추론 성능 그래프
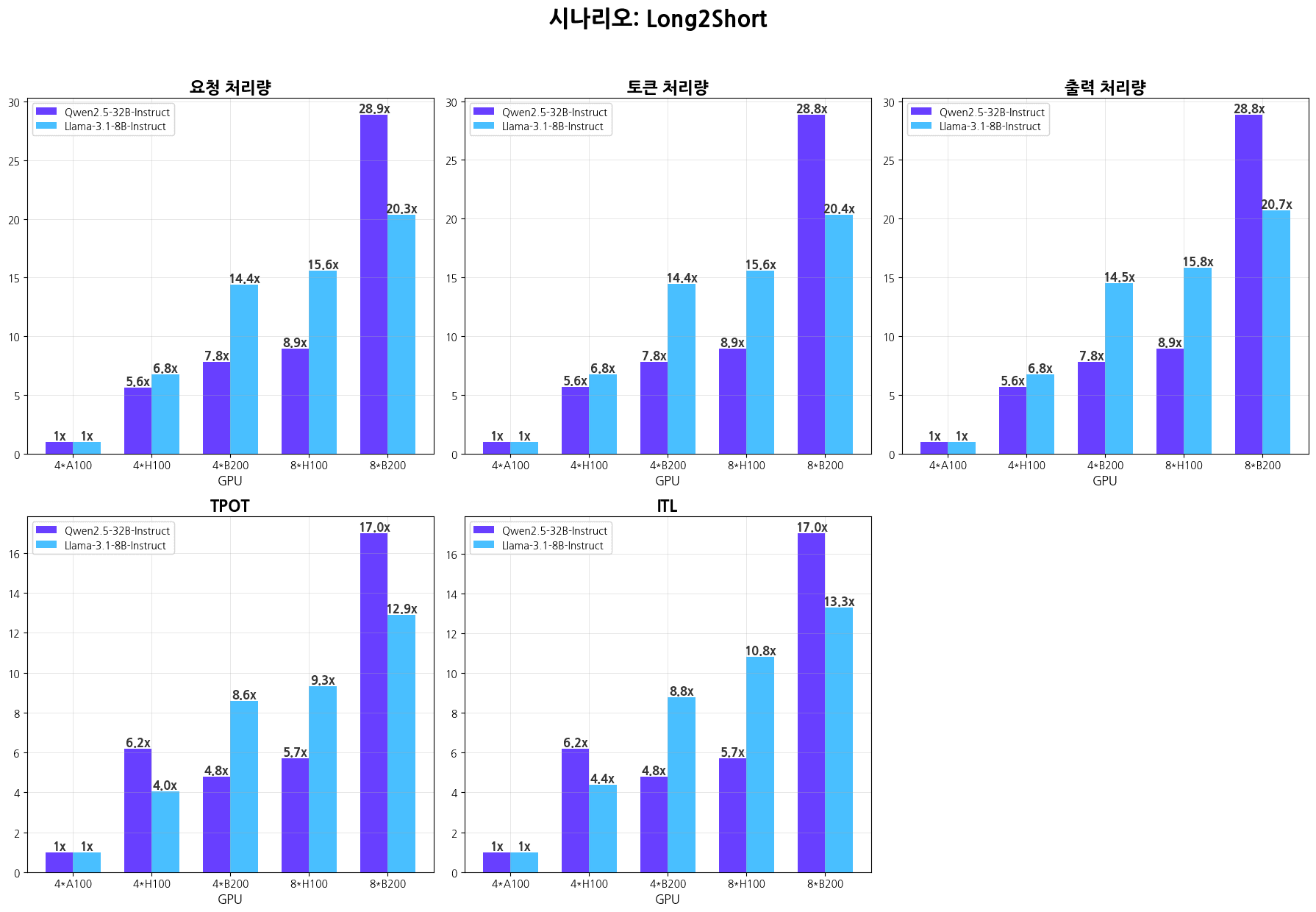
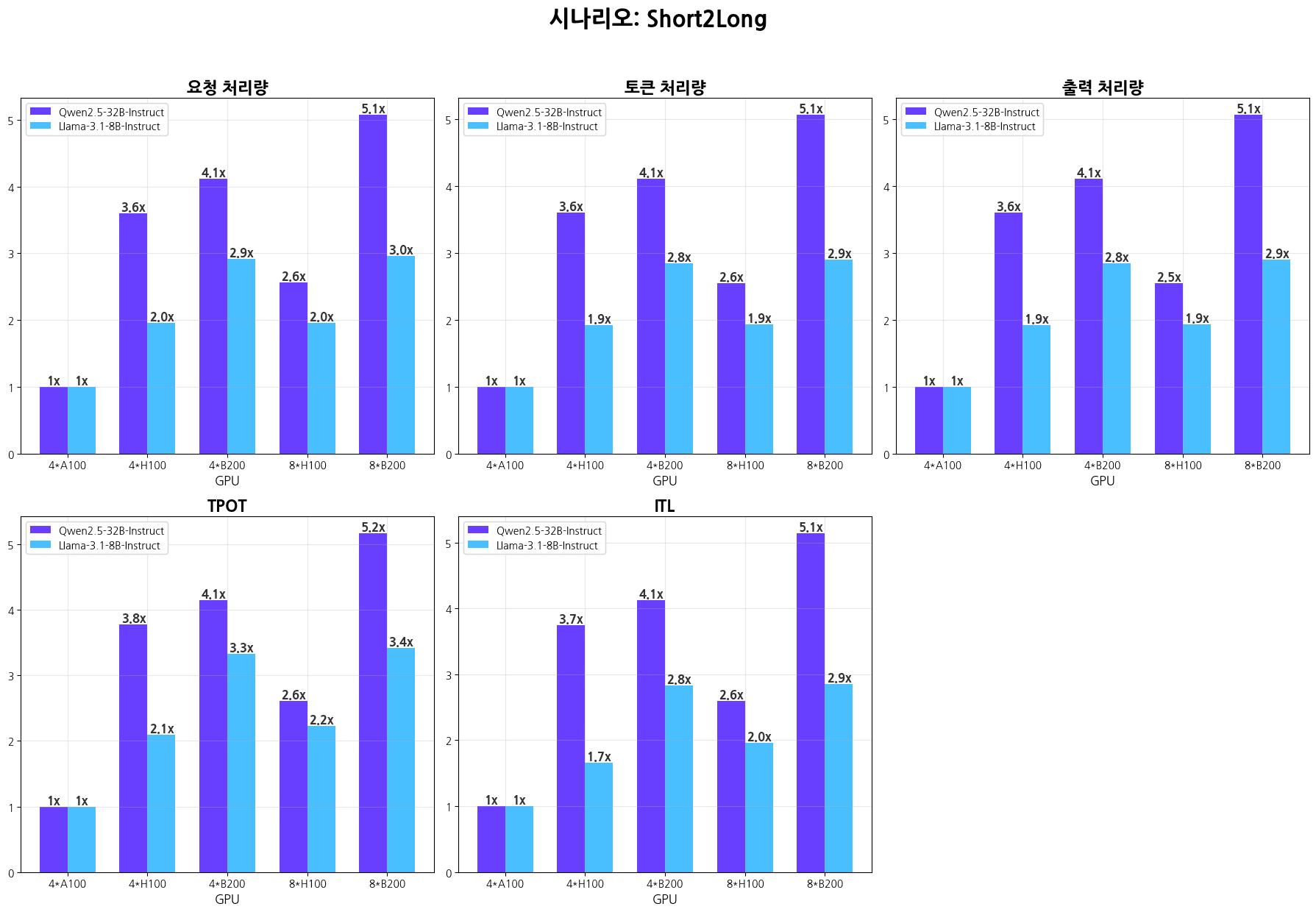
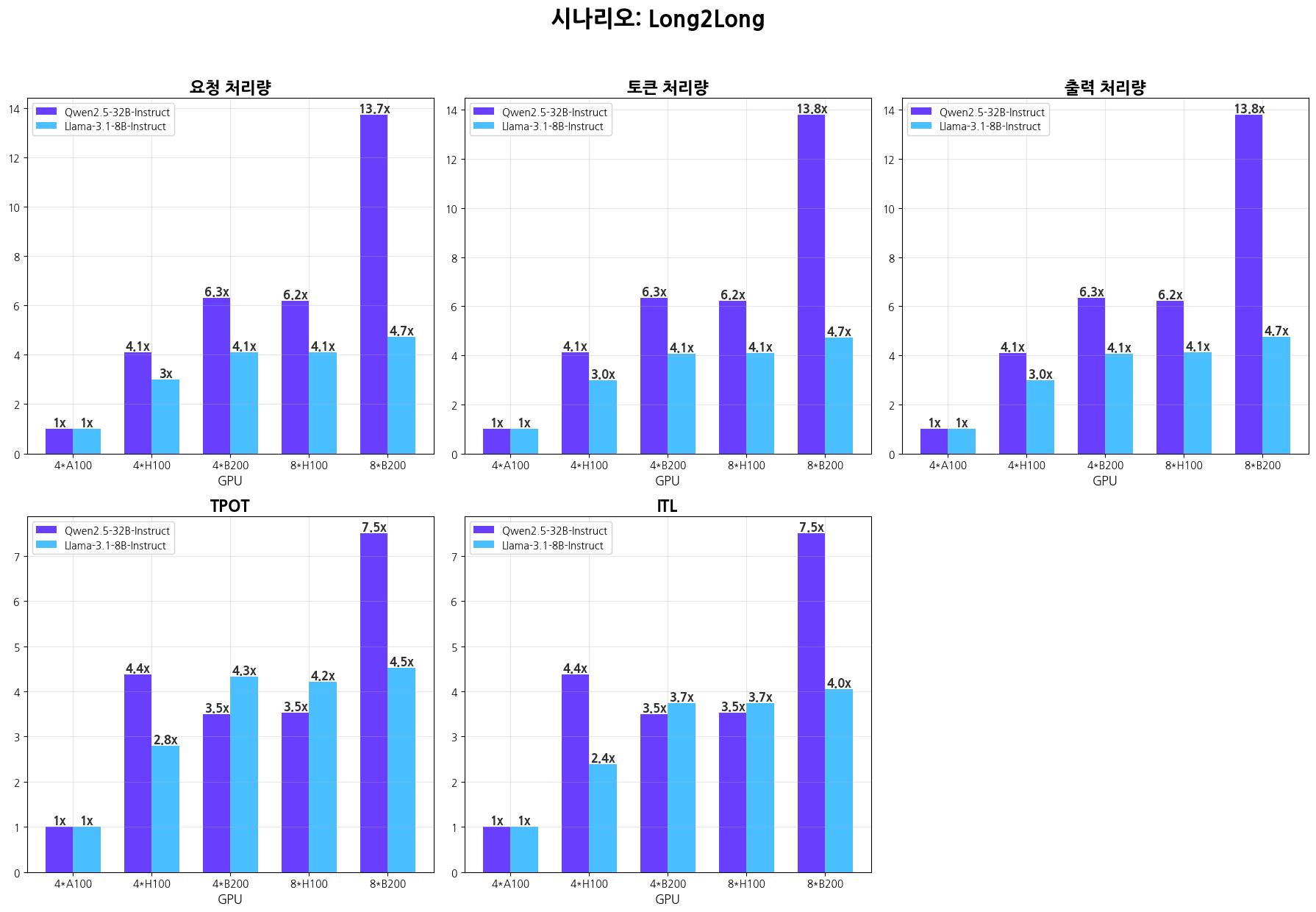
시나리오별 추론 성능표
- 4*A100
| 시나리오 | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| Short2Long | 0.50 | 0.95 | 3650.25 | 2417.94 | 3392.62 | 1931.97 | 53.28 | 81.14 | 46.84 | 80.60 |
| Long2Long | 0.22 | 0.22 | 3361.41 | 2222.10 | 1568.44 | 448.94 | 110.63 | 190.13 | 95.49 | 190.13 |
| Long2Short | 0.99 | 0.37 | 8468.62 | 3189.49 | 455.67 | 189.86 | 200.63 | 467.98 | 197.01 | 468.76 |
| Average | 0.57 | 0.51 | 5160.09 | 2609.84 | 1805.58 | 856.92 | 121.51 | 246.42 | 113.11 | 246.50 |
- 4*H100
| 시나리오 | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| Short2Long | 0.98 | 3.42 | 7014.91 | 8710.56 | 6516.28 | 6963.01 | 25.51 | 21.52 | 28.22 | 21.55 |
| Long2Long | 0.66 | 0.90 | 10010.41 | 9124.85 | 4698.88 | 1839.23 | 39.62 | 43.48 | 40.01 | 43.48 |
| Long2Short | 6.70 | 2.09 | 57253.30 | 18001.63 | 3078.48 | 1071.60 | 49.58 | 75.60 | 44.84 | 75.60 |
| Average | 2.78 | 2.14 | 24759.54 | 11945.68 | 4764.55 | 3291.28 | 38.24 | 46.87 | 37.69 | 46.88 |
- 4*B200
| 시나리오 | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| Short2Long | 1.46 | 3.91 | 10386.39 | 9932.15 | 9643.28 | 7933.78 | 16.02 | 19.59 | 16.55 | 19.55 |
| Long2Long | 0.90 | 1.39 | 13625.56 | 14104.94 | 6361.54 | 2849.71 | 25.57 | 54.37 | 25.49 | 54.37 |
| Long2Short | 14.28 | 2.90 | 122181.43 | 24957.56 | 6610.04 | 1485.71 | 23.34 | 97.70 | 22.41 | 97.70 |
| Average | 5.55 | 2.73 | 48731.13 | 16331.55 | 7538.29 | 4089.73 | 21.64 | 57.22 | 21.48 | 57.21 |
- 8*H100
| 시나리오 | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| Short2Long | 0.98 | 2.43 | 7064.54 | 6168.16 | 6564.26 | 4926.52 | 23.89 | 31.07 | 23.92 | 31.01 |
| Long2Long | 0.90 | 1.36 | 13720.65 | 13791.44 | 6444.70 | 2786.37 | 26.25 | 53.97 | 25.50 | 53.97 |
| Long2Short | 15.41 | 3.30 | 131880.13 | 28410.60 | 7194.36 | 1691.27 | 21.53 | 82.22 | 18.24 | 82.22 |
| Average | 5.76 | 2.36 | 50888.44 | 16123.40 | 6734.44 | 3134.72 | 23.89 | 55.75 | 22.55 | 55.73 |
- 8*B200
| 시나리오 | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| Short2Long | 1.48 | 4.82 | 10588.73 | 12244.67 | 9830.86 | 9781.01 | 15.59 | 15.72 | 16.40 | 15.69 |
| Long2Long | 1.04 | 3.02 | 15894.01 | 30653.16 | 7449.34 | 6193.05 | 24.48 | 25.36 | 23.62 | 25.36 |
| Long2Short | 20.13 | 10.69 | 172354.79 | 91981.50 | 9442.95 | 5475.60 | 15.56 | 27.55 | 14.82 | 27.55 |
| Average | 7.55 | 6.18 | 66279.18 | 44959.78 | 8907.72 | 7149.89 | 18.54 | 22.88 | 18.28 | 22.87 |
학습 성능표
| GPU | GPU당 최대 배치 사이즈 | 단일 배치 처리량 | 최대 처리량 | |||
|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| 8*B200 | 216 | 146 | 12.2 | 10.0 | 44.9 | 27.8 |
| 4*B200 | 202 | 132 | 6.6 | 5.8 | 32.1 | 19.6 |
| 8*H100 | 72 | 52 | 6.4 | 6.2 | 29.8 | 19.3 |
| 4*H100 | 62 | 45 | 4.6 | 4.1 | 22.9 | 15.8 |
| 4*A100 | 60 | 42 | 1.3 | 1.4 | 4.4 | 4.2 |
시나리오 평균 추론 성능표
| GPU | 요청 처리량 (req/s) | 토큰 처리량 (tokens/s) | 출력 처리량 (tokens/s) | TPOT (ms) | ITL (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | Llama | Qwen | |
| 8*B200 | 7.55 | 6.18 | 66279.18 | 44959.78 | 8907.72 | 7149.89 | 18.54 | 22.88 | 18.28 | 22.87 |
| 8*H100 | 5.76 | 2.36 | 50888.44 | 16123.40 | 6734.44 | 3134.72 | 23.89 | 55.75 | 22.55 | 55.73 |
| 4*B200 | 5.55 | 2.73 | 48731.13 | 16331.55 | 7538.29 | 4089.73 | 21.64 | 57.22 | 21.48 | 57.21 |
| 4*H100 | 2.78 | 2.14 | 24759.54 | 11945.68 | 4764.55 | 3291.28 | 38.24 | 46.87 | 37.69 | 46.88 |
| 4*A100 | 0.57 | 0.51 | 5160.09 | 2609.84 | 1805.58 | 856.92 | 121.51 | 246.42 | 113.11 | 246.50 |