H100, 시간당 2,562원부터 — 단 한달간
스팟 GPU로 최저가 시작하기

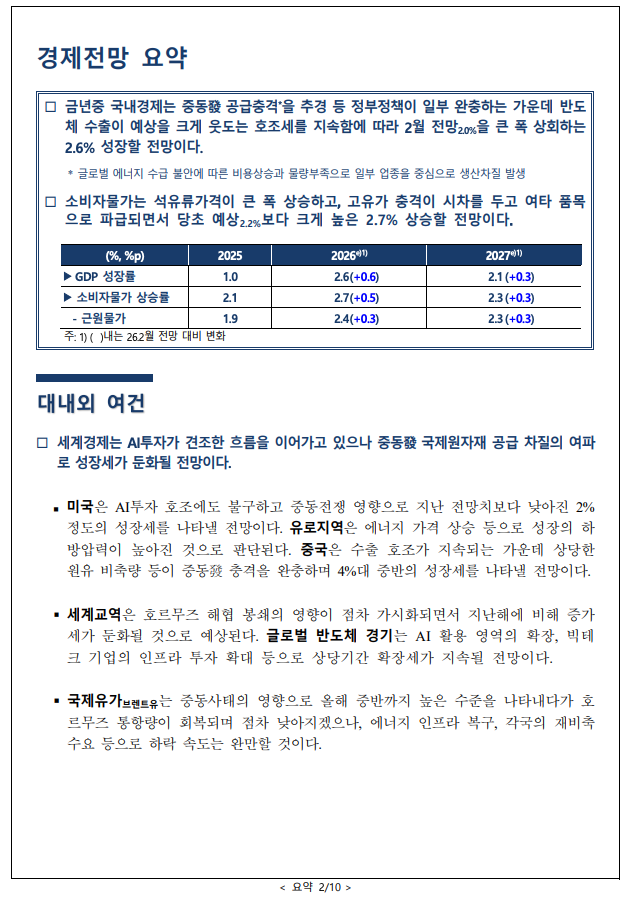
병합 셀, 다중 헤더, 불규칙한 레이아웃. 기존 OCR이 놓치던 표 구조까지 정확도 95.3%로 구현해내는 국내 최상위 표 추출 모델입니다.
정확도 95.3% · OpenAI 호환 API · Dedicated 인스턴스 · HTML·Markdown·CSV·JSON 출력
항목 | 내용 |
|---|---|
용도 | 표 이미지를 행·열 구조가 유지된 HTML로 변환 |
정확도 | 최대 95.3% |
입력 | 스크린샷·스캔 문서·문서 사진 등 표가 포함된 이미지 |
출력 | HTML(권장)·Markdown·CSV·JSON |
연동 | OpenAI 호환 Chat Completions API : endpoint, 모델명만 교체 |
제공 방식 | Dedicated(전용 인스턴스), 고객사 맞춤형 파인튜닝 지원 |
모델 ID | eliceai/helpy-table-vision |
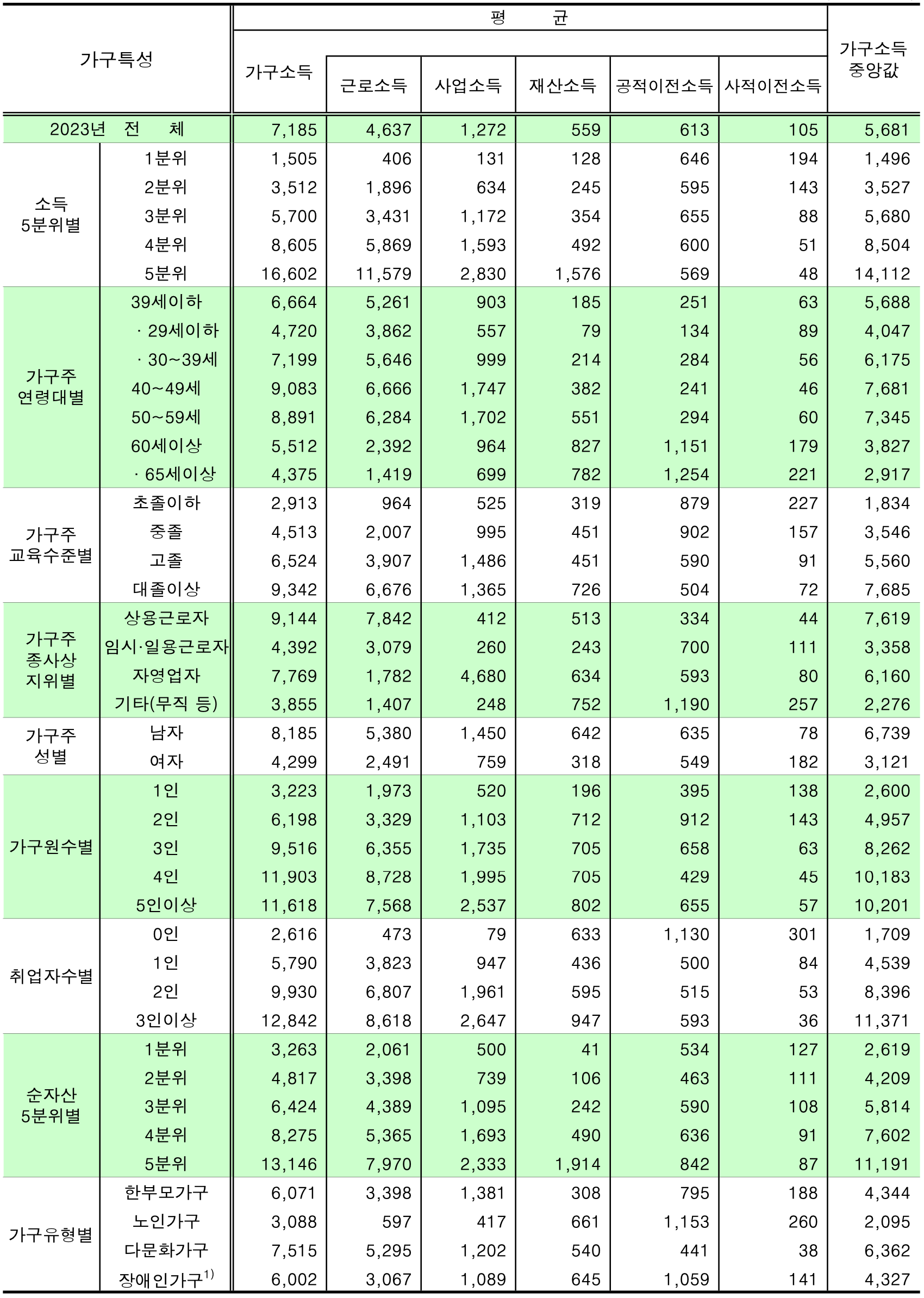
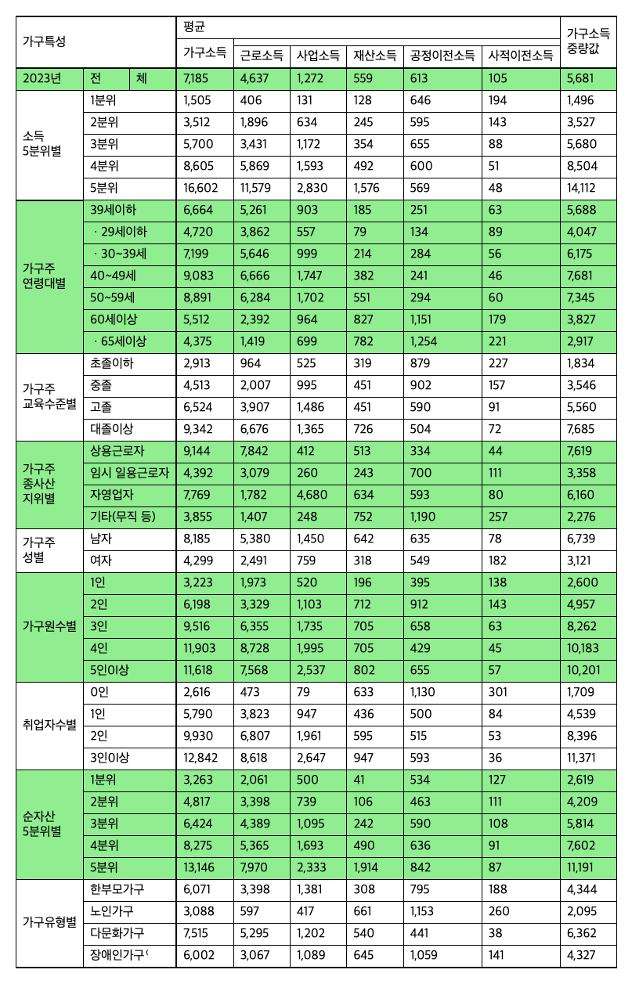
병합 셀과 다중 헤더의 행·열 관계를 유지한 채로 출력합니다. 변환된 HTML은 그대로 브라우저에 표시하거나 RAG 시스템에 활용할 수 있습니다. 복잡한 행·열 구조는 물론, 강조색·볼드 같은 서식까지 그대로 유지합니다.
입력 : 다중 헤더와 병합 셀이 중첩된 통계표 이미지 | 변환 결과 : 행·열 구조와 병합 관계부터 강조색 그대로 살아 있는 HTML 출력 |
|---|---|
|
|
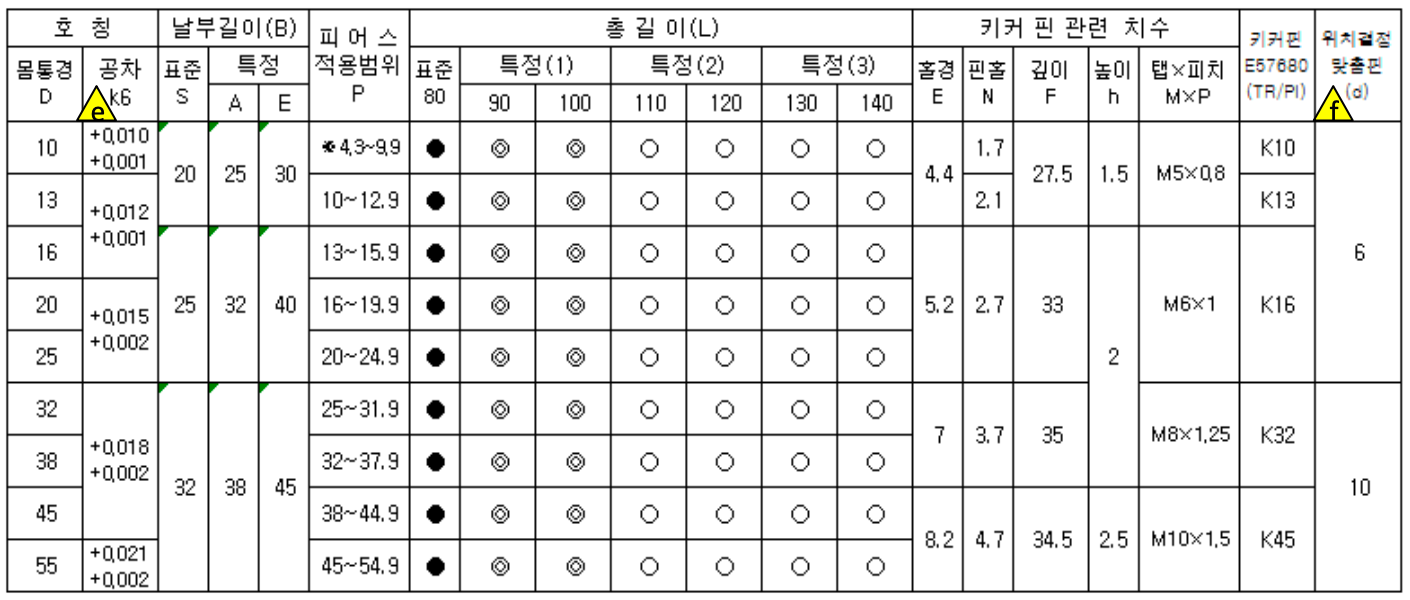
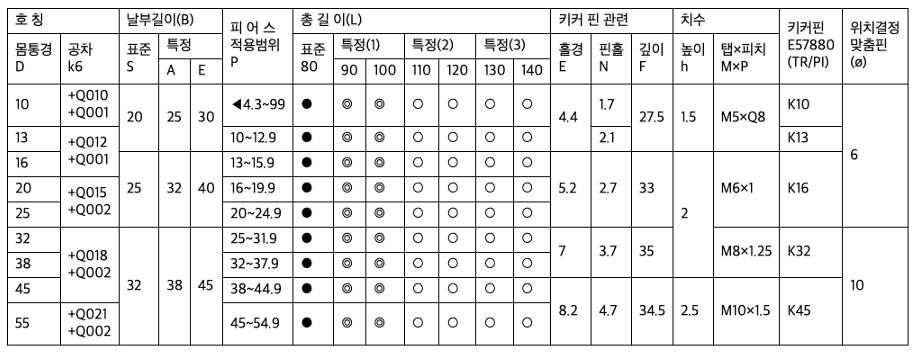
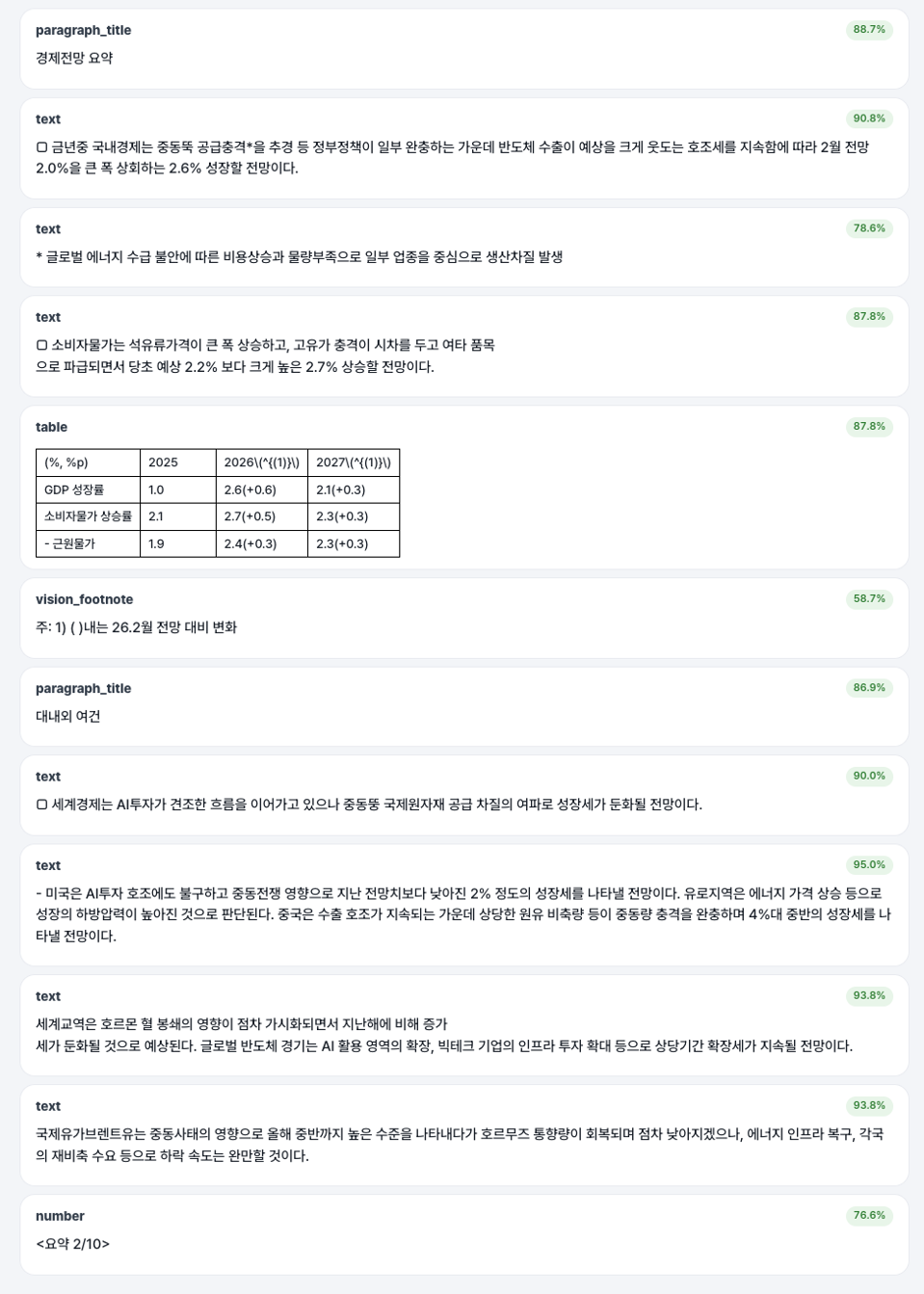
다른 입력 예시: 불규칙한 셀 병합과 기호가 섞인 산업 기술표준표도 처리합니다.
입력 전: 불규칙한 셀병합과 기호가 섞인 산업 기술표준표 | 입력 후: 셀병합 등을 거의 유사하게 HTML로 구현 |
|---|---|
|
|
기존 OCR은 병합 셀, 다중 행 헤더, 불규칙한 셀과 같은 구조를 단순 텍스트로 변환합니다. Helpy Table Vision은 원본의 구조를 그대로 유지하여 표의 맥락을 그대로 구현합니다.
OpenAI 클라이언트 라이브러리를 그대로 사용할 수 있도록 설계하여 기존 서비스의 코드 변경을 최소화합니다.
import base64
from openai import OpenAI
client = OpenAI(
base_url="https://mlapi.run/abc-1234-xyz/v1",
api_key="your-api-key-here",
)
with open("table.png", "rb") as f:
b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="eliceai/helpy-table-vision",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Table Recognition:"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{b64}"}},
],
}],
temperature=0.0,
max_tokens=15000,
)
print(response.choices[0].message.content) # output in otsl (Optimized Table Structure Language) format
저지연 추론에 최적화되어 실시간 서비스와 대량 배치 처리 모두 가능합니다.
구분 | 사양 |
|---|---|
입력 형식 | 이미지 (스크린샷, 스캔 문서, 문서 사진 등) |
입력 추가 | 추출 형식을 지정하는 텍스트 프롬프트 |
출력 형식 | HTML(최적화·권장), Markdown, CSV, JSON |
API 규격 | OpenAI 호환 Chat Completions API |
모델 ID | eliceai/helpy-table-vision |
제공 방식 | Dedicated (전용 인스턴스) |
도메인 학습 | 고객사 맞춤형 파인튜닝 지원 |
표 이미지를 입력받아 시각적 구조를 분석하고, 셀 단위 관계를 추론해 HTML 마크업으로 변환합니다.
STEP 1 · 이미지 입력 표가 포함된 이미지(스크린샷·스캔본·문서 사진)와 추출 형식을 지정하는 프롬프트를 함께 입력합니다.
STEP 2 · 시각적 구조 분석 표의 행·열 경계, 병합된 셀, 헤더 계층을 인식합니다.
STEP 3 · 구조화 마크업 변환 인식된 구조를 HTML(rowspan·colspan 포함)·Markdown·CSV·JSON 등 요청한 형식으로 출력합니다.
*한국어 비정형 문서 벤치마크 기준
모델 | 테이블 파싱 정확도 |
|---|---|
Helpy Table Vision | 95.3% |
GPT-5 | 64.6% |
Qwen3 VL 30B | 50.2% |
*실제 도입 환경에서의 성능은 표의 복잡도와 이미지 품질에 따라 달라질 수 있습니다. PoC 단계에서 고객사 실제 데이터로 검증할 수 있습니다.
표뿐 아니라 단락, 차트, 수식, 이미지까지 문서 전체의 데이터화가 필요하다면 Helpy Document Vision을 사용하시면 됩니다.
Helpy Document Vision은 Helpy Table Vision을 내포하고 있어 문서에서 표가 감지되면 자동으로 호출합니다.
입력 예시 : 표·단락·제목이 혼재된 실제 보고서 페이지 | 변환 결과 |
|---|---|
|
|
변환 결과 (계층적 JSON) : 페이지의 각 요소를 종류(label), 내용(content), 좌표(coordinate)로 구조화하고, 이미지 및 로고는 설명(description)까지 생성합니다. 표가 감지되면 Helpy Table Vision이 자동 호출되어 해당 요소를 HTML로 채웁니다.
{
"page_count": 168,
"pages": [
{
"elements": [
{ "label": "header", "content": "ISSN 2288-7083" },
{ "label": "paragraph_title", "content": "경제전망 Indigo Book 2026년 5월" },
{ "label": "table", "content": "<table> ... </table>" },
{ "label": "footer_image", "description": "한국은행 로고. 파란 원형 엠블럼과 ..." }
]
}
]
}
구분 | Helpy Table Vision | Helpy Document Vision |
|---|---|---|
역할 | 표 전문 추출 | 문서 전체 구조 분석 |
입력 | 이미지 (스크린샷, 스캔 등) | PDF, PPT, PPTX, PNG, JPEG, JPG |
출력 형식 | HTML, Markdown, CSV, JSON | 계층적 JSON |
API 규격 | OpenAI 호환 Chat Completions | multipart/form-data 비동기 |
적합 워크로드 | 표 데이터가 핵심인 워크플로우, 기존 OpenAI 서비스 마이그레이션 | RAG·AI 에이전트 데이터 파이프라인, 비정형 문서 전반 처리 |
전용(Dedicated) 인스턴스 기반으로 다른 고객과 자원·데이터를 격리해 운영합니다. 금융, 의료, 공공기관 등 민감 데이터를 다루는 환경에 적합합니다.
보안 항목 | 내용 |
|---|---|
CSAP 인증 | 공공기관 도입 필수 기준 충족 |
ISO 27001·27701 | 국제 표준 정보보호, 개인정보 관리체계 |
국내 리전 운영 | 데이터 해외 반출 없음 |
Dedicated 인스턴스 | 자원·데이터 완전 격리 |
AI PMDC 연계 | 모듈형 데이터센터 연계 시 완전 폐쇄망 운영 |
Q. 어떤 이미지 형식을 지원하나요? 표가 포함된 PNG, JPEG, JPG 이미지를 지원합니다. 스크린샷, 스캔본, 문서 사진 모두 처리할 수 있습니다. 다만 해상도가 극도로 낮거나 압축 노이즈가 심한 이미지는 추출 정확도가 저하될 수 있습니다.
Q. 표가 없는 일반 이미지도 분석할 수 있나요? Helpy Table Vision은 표 추출 전용 모델입니다. 표가 포함되지 않은 이미지에서는 성능을 보장하기 어렵습니다. 단락·차트·수식 등 표 외 요소가 포함된 문서를 처리하려면 Helpy Document Vision을 활용해 주세요.
Q. 기존 OpenAI 기반 서비스에 바로 연동할 수 있나요? 가능합니다. Helpy Table Vision은 OpenAI 호환 Chat Completions API 규격을 따르므로, 기존 OpenAI 클라이언트 라이브러리를 그대로 사용할 수 있습니다. endpoint URL과 모델명만 변경하면 즉시 교체됩니다.
Q. 어떤 출력 형식이 가장 정확한가요? HTML이 가장 높은 구조적 정확도를 제공합니다. 모델이 rowspan·colspan을 포함한 HTML 출력에 최적화되어 있기 때문입니다. JSON, Markdown도 지원하지만 복잡한 병합 셀 구조를 표현하는 데는 HTML보다 한계가 있을 수 있습니다.
Q. 다른 표 추출 솔루션·문서 파싱 API와 무엇이 다른가요? Helpy Table Vision은 한국어 비정형 문서에서 표 추출 정확도 95.3%를 기록한 표 전문 모델입니다.(같은 벤치마크에서 GPT-5는 64.6%, Qwen3 VL은 50.2%를 달성하며 범용 모델 대비 우수한 결과를 기록했습니다.) 범용 문서 파싱 API가 표를 단순 텍스트나 셀 나열로 풀어내는 것과 달리, 병합 셀과 다중 헤더의 rowspan·colspan 관계를 그대로 보존한 HTML로 출력합니다. OpenAI 호환 API라 기존 서비스에 코드 변경 없이 교체할 수 있고, 고객사 데이터로 파인튜닝하면 도메인 특화 표까지 정확도를 끌어올릴 수 있습니다.
Q. 도메인 맞춤 학습이 가능한가요? 가능합니다. 수백 건 수준의 데이터 학습만으로도 고문서나 특수 도메인의 표를 정확히 분석할 수 있습니다. 도입 전 엘리스 팀과 최적화 방향을 함께 논의할 수 있습니다.
Q. 대기업 보안 환경에서도 도입 가능한가요? 글로벌자동차그룹 R&D 환경에서 고객사 보안 가이드라인을 준수해 시스템을 구축한 실적이 있습니다. CSAP IaaS 및 ISO 27001・27701 인증을 받은 엘리스클라우드에서 운영되며, AI PMDC(모듈형 데이터센터) 연계로 완전 폐쇄망 운영까지 지원합니다.
Q. Helpy Document Vision과 어떻게 다른가요? Helpy Table Vision은 표 추출 전용 모델로, OpenAI 호환 API와 저지연 추론에 최적화되어 있습니다. Helpy Document Vision은 표 외에도 단락·차트·수식·이미지를 포함한 문서 전체를 분석하는 모델입니다. 표 데이터만 필요하다면 Helpy Table Vision을, 문서 전체 구조가 필요하다면 Helpy Document Vision을 선택하세요. Helpy Document Vision은 내부적으로 Helpy Table Vision을 호출합니다.
모델 제공자
Elice AI
모델 종류
Image Text To Text
사용 방식 및 요금
Serverless
Dedicated
인스턴스 사용 시간
모델 ID
eliceai/helpy-table-vision