과기부 주최 전국민 AI 경진대회 개최
접수하기



NVIDIA-Nemotron-3-Ultra-550B-A55B는 NVIDIA가 개발한 프런티어급 추론·에이전트 LLM으로, 최대 1M 토큰 컨텍스트를 활용해 대용량 문서와 코드베이스 추론에 특화되어 있습니다. Latent Mixture-of-Experts(LatentMoE) 구조로 총 550B 중 토큰당 약 55B만 활성화해 효율을 높였고, 토큰을 더 작은 latent 차원으로 투영해 라우팅·연산함으로써 바이트당 정확도(accuracy per byte)를 끌어올립니다. Mamba-2·MoE·Attention을 교차 배치한 Mamba2-Transformer 하이브리드 아키텍처에 Multi-Token Prediction(MTP)을 더해 생성 속도를 높였으며, 약 20T 토큰을 NVFP4 레시피로 사전학습했습니다. 답변을 내기 전 추론 과정(reasoning trace)을 먼저 생성하고, 추론 기능은 필요에 따라 켜고 끌 수 있습니다. 가중치·데이터·학습 레시피가 모두 공개된 오픈 모델입니다.
구분 | 내용 |
|---|---|
제공자 | NVIDIA |
종류 | Text → Text |
아키텍처 | Mamba2-Transformer 하이브리드 LatentMoE + MTP |
파라미터 | 550B total / 55B active (MoE) |
사전학습 | 약 20T tokens · NVFP4 양자화 인식 학습 |
컨텍스트 | 최대 1,000,000 tokens |
입력 / 출력 | Text / Text |
추론 모드 | 기본 ON · 중간 강도(medium_effort) · OFF 전환 |
인터페이스 | OpenAI 호환 Chat Completions |
언어 | EN, KO, JA, ZH, FR, ES, DE, IT, HI, PT-BR (10종) |
라이선스 | OpenMDW-1.1 (상업·비상업 모두 가능) |
데이터 컷오프 | pre-train 2025-09 / post-train 2026-05 |
DeepSeek-V4, Kimi-K2.6, GLM-5.1, Qwen-3.5, MiniMax-2 같은 글로벌 최상위 오픈웨이트 모델과 견줄 만한 성능을 보입니다. 추론·지식, 수학, 코딩·에이전트, 장문 컨텍스트, 다국어까지 폭넓은 영역에서 고르게 강점을 나타냅니다.
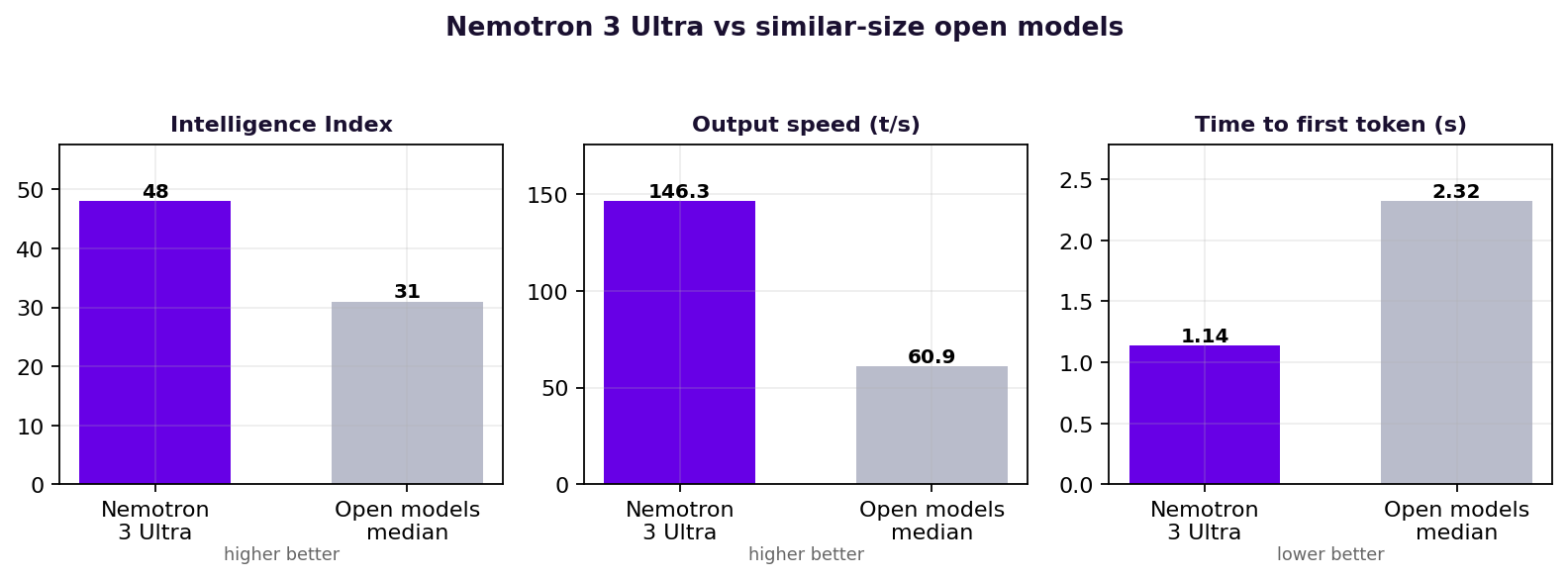
*모든 점수는 NVIDIA 공식 모델카드 기준이며, 별도 표기가 없으면 도구 없이 측정한 값입니다.
복잡한 인프라 구성 없이 엘리스클라우드 ML API로 Nemotron-3-Ultra-550B-A55B을 바로 호출할 수 있습니다.
|
|
|
|
신규 모델 상시 추가 | 인프라 세팅 없이 즉시 사용 | 원화 결제 | 엘리스클라우드 GPU 연동 |
검증된 최신 오픈소스 모델 상시로 업데이트 | 서버·GPU 세팅 없이 API 호출만으로 즉시 사용 | 환율 걱정없이 원화로 간편하게 결제 | 전용 자원 혹은 파인튜닝이 필요한 경우 엘리스클라우드 GPU 즉시 연동 |
OpenAI 호환 API로, 몇 줄의 코드만으로 바로 호출할 수 있습니다. 최상의 성능을 위해 temperature=1.0, top_p=0.95를 권장하며, 추론 모드는 기본 ON, 비추론 모드는 enable_thinking=False로 전환합니다.
curl -X POST https://YOUR_ENDPOINT_URL/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"model": "nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain mixture-of-experts models in simple terms."}
],
"max_tokens": 16000,
"temperature": 1.0,
"top_p": 0.95,
"chat_template_kwargs": {"enable_thinking": false}
}'from openai import OpenAI
client = OpenAI(base_url="YOUR_ENDPOINT_URL/v1", api_key="YOUR_API_KEY")
# 기본 호출 (추론 모드 ON)
resp = client.chat.completions.create(
model="nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4", # 엘리스 ML API 모델 ID
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "이 보고서에서 핵심 리스크 3가지를 정리해 줘."},
],
max_tokens=16000,
temperature=1.0,
top_p=0.95,
)
print(resp.choices[0].message.content)
# 비추론 모드 (빠른 응답)
resp = client.chat.completions.create(
model="nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4",
messages=[{"role": "user", "content": "한 줄로 요약해 줘."}],
extra_body={"chat_template_kwargs": {"enable_thinking": False}},
)POST /v1/chat/completionstemperature=1.0, top_p=0.95 (추론 ON 기본 · 비추론 enable_thinking=False · 추론량 절감 medium_effort=True)chat_template_kwargs에 force_nonempty_content=True 추가 (도구 호출과 추론을 함께 파싱하려면 enable_thinking=True도 함께 설정)모델 제공자
nvidia
모델 종류
Text Generation
사용 방식 및 요금
Serverless
₩913/1M input tokens
₩5,220/1M output tokens
Dedicated
모델 ID
nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4



